About datasets
What is a dataset?
For general usage, dataset is another way of saying 'data' or 'environmental information'. It refers to a collection of information organised in a particular format. For example, a dataset may be:
• a table with rows and columns, such as readings from dust or water quality monitoring stations
• a report, such as an Environmental Impact Statement
• an image file, such as photographs or maps
• a geospatial file, containing data associated with locations, which means it can be viewed on a map.
How do I view a dataset?
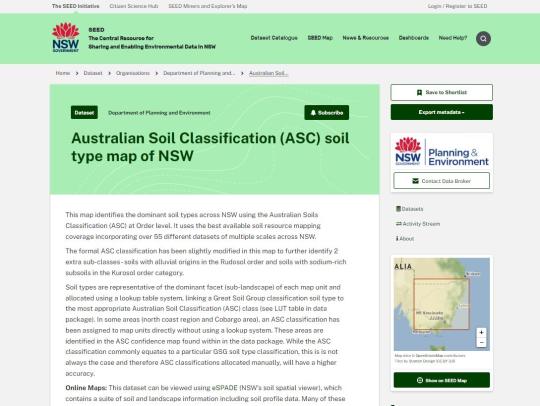
To view an individual dataset, select the title of the dataset to open the Dataset View page:
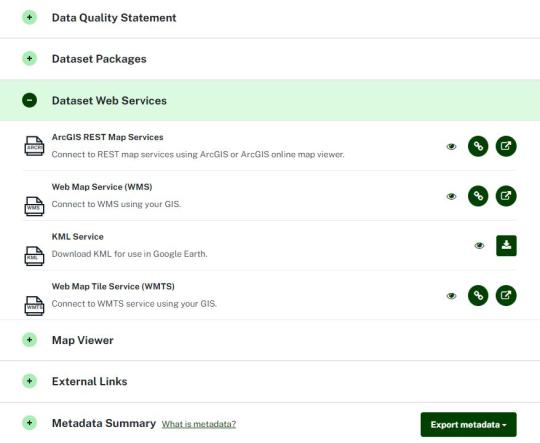
Understanding the data
The following information resources are provided for every dataset in SEED:
| Description | The dataset description is published in SEED exactly as provided by the person(s) who collected the data, to maintain consistency with other sites and publications. |
| Data Quality Statement | The Data Quality Statement describes the key characteristics of the data so that potential users can make informed decisions about fitness for use |
| Metadata Statement | The Metadata Statement contains information that describes the dataset, such as when and how it was created. It includes information such as the custodian (manager) of the data, keywords (related subjects), extent (the geographical area covered by the data) and any limitations on how it is to be used. The Metadata may be provided in PDF (document) and/or XML (web code) format |
Viewing the data
Resources for viewing the data can be found under various expandable headings underneath a dataset’s description. To display the resources, click on the ‘expand’ icon next to the relevant heading. For more information on how to use the software resources go to this page.